
























TECHNICAL SUPPORT


Published 2026-01-19
You designed a beautiful microservices architecture. Each service is like a gear in a precision clock, running independently and flawlessly. Then, you need them to collaborate. Data needs to flow through gears like water—and suddenly, everything slows down. Latencies in one service fall like dominoes, queries become lengthy, and the elegance of the entire system is lost. What's the problem? Not the design of your services, but the way they "chat".

We often fall into a misunderstanding: as long as the interface is clearly defined, data sharing will naturally be smooth. But the reality is that when hundreds of microservices are online at the same time, every data request may turn into a mini war. Bandwidth is squeezed, response times fluctuate, critical data is versioned differently between services... it feels like conducting a symphony orchestra, but each musician is reading a different score.
Imagine that you are responsible for an order processing system. Order service, inventory service, user service, logistics service... Each service needs to know part of the "order" information, but not all. What is the traditional approach? Either let the order service become a data hub and bear all the pressure; or let the services call each other to form a complex call chain. The former can easily become a single point of failure, while the latter can make troubleshooting like a maze.
True data sharing is not about simply opening up database permissions, nor is it about endlessly copying data copies. It's about precision, timeliness and boundaries. Precision means that each service only gets the part of the data it needs, no more and no less. Timeliness means that the data is fresh, but not all data needs to be updated in "real time" - inventory numbers need to be real-time, but the user's historical address record may allow for a delay of several minutes. Boundaries mean clear division of data responsibilities: who produces, who consumes, and who is responsible for maintaining the source of data truth.
"Then what should we do? Do we need to rewrite the entire communication layer?" A friend who is responsible for system integration once asked me. The answer is usually simpler: you need a set of principles, not a one-size-fits-all tool.
kpowerAfter observing hundreds of actual cases, we found that elegant microservice data sharing often revolves around a few core habits. This is not a disruptive technology, but a mindset shift.
Distribute by "need", not by "permission". It's like in a company, the financial department doesn't need to know the real-time access records of each employee, and the administrative department doesn't need to see the R&D code base. Define a clear list of data requirements for each microservice. For requests outside the list, the system should gracefully reject or return minimal information. This reduces unnecessary data transmission load and reduces coupling between services.
Establish a "data station" instead of a "data broadcast". Instead of having each service bother the data producer when needed, it would be better to set up an intermediate caching layer - but this is not a simple Redis cache. We call it the "data station", which only stores aggregated data that is needed by multiple services and allows a slight delay. For example, a "popular product list" data can be generated by product services and put into the post. Orders, marketing, recommendations and other services can be obtained from here without repeatedly querying the product database. Producers only push changes, consumers subscribe on demand, and everyone gets what they want.
Furthermore, label the data with a “shelf life” label. Not all data is worth synchronizing right away. User nickname changed? It can be processed asynchronously and synchronized to all related services within a few minutes. Payment successful status? This requires near real-time notification of order and inventory services.kpowerThe approach is to define different synchronization urgency levels for different data types and architecturally support this differentiated flow speed. This avoids the congestion caused by putting all the data in the "emergency channel".
A team leader who adopted a similar idea shared: "The most intuitive change is that our system logs suddenly became clear. In the past, the data flow was like a mess, but now you can clearly see where the data comes from, where it passes, and who consumes it. Debugging time has been reduced by about 70%."
When you straighten out data sharing, some unexpected positive side effects emerge. The overall observability of the system will increase because the data flow becomes traceable. New services will be added faster, and you only need to define its data requirements without worrying about it bringing down existing systems. More importantly, collaboration between teams will be clearer - the data contract becomes a clear agreement between services, reducing quarrels in ambiguous areas.
Does this sound a bit idealistic? It actually starts with some very pragmatic choices. For example, define for each core data its "owner service" from the beginning. For example, direct database access between services is strictly avoided and all exchanges are through well-defined APIs or message queues. Another example is to establish a set of lightweight monitoring to focus on the delay and error rate of data calls between services, rather than waiting for users to complain before taking action.
If your system is feeling the pain of data sharing, don't rush to reinvent the wheel. Start with a map: Draw a sketch of all your microservices and their current data dependencies. You may be surprised to find that some dependencies are unnecessary.
Then, find out the most painful "data chain" - maybe the order creation process, maybe the user profile update path. Try to apply a principle above: establish a clear data output and consumption contract for this chain, and introduce a "data station" to decouple direct calls. Performance changes before and after measurement. Often, a small success can pave the way for the entire architecture to evolve.
In the world of microservices, services are independent, but data is the common blood. The principle of sharing data is not to build thicker blood vessels, but to design a smarter blood circulation system. It allows every cell (service) to obtain nutrients (data) in a timely manner without overburdening the heart (core service). In this invisible war, the outcome does not depend on how many technology stacks you have, but on whether you can act like a smart designer and make data flow a natural and efficient order.kpowerWhat is understood is the art of constructing this order.
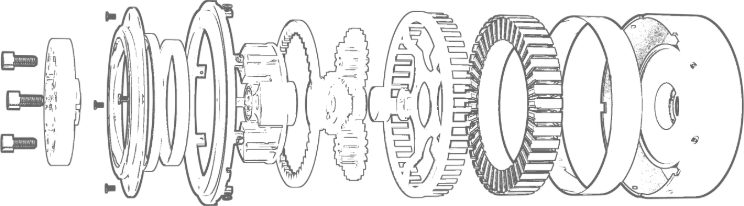
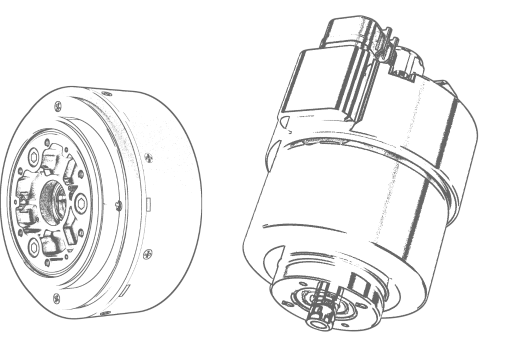
Established in 2005, Kpower has been dedicated to a professional compact motion unit manufacturer, headquartered in Dongguan, Guangdong Province, China. Leveraging innovations in modular drive technology, Kpower integrates high-performance motors, precision reducers, and multi-protocol control systems to provide efficient and customized smart drive system solutions. Kpower has delivered professional drive system solutions to over 500 enterprise clients globally with products covering various fields such as Smart Home Systems, Automatic Electronics, Robotics, Precision Agriculture, Drones, and Industrial Automation.
Update Time:2026-01-19
Contact Kpower's product specialist to recommend suitable motor or gearbox for your product.






















